
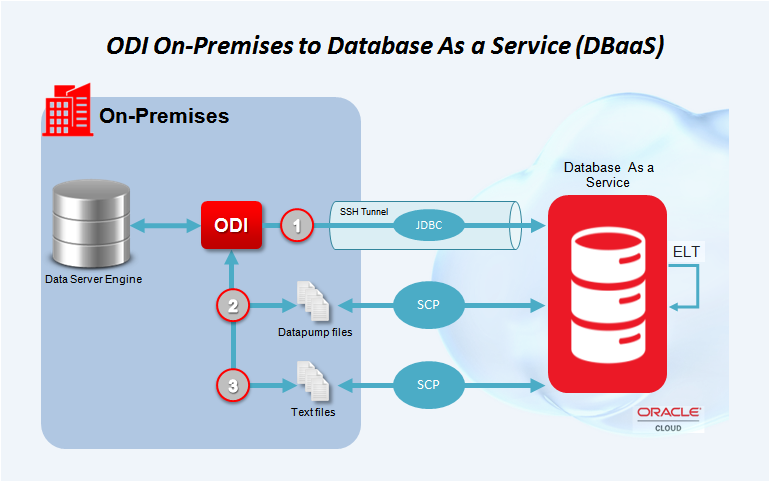
Introduction – Oracle Data Integration (ODI)
Introduction – Oracle Data Integration ( ODI )
Data Integration:
“Data integration is the combination of technical and business process used to combine data from disparate sources into meaningful and valuable information”.
Data integration ensures that information is timely, accurate and consistent across complex systems.
Types of Integration:
- Data Integration (large volume of data Integration)
- Event Integration (Event Drive Architecture)
- Service Integration ( Service Oriented Architecture)
ODI features:
- Oracle Data Integration features an active integration platform that includes all styles of data integration : data-based, event-based and service-based.
- Capable of transforming large volume of data efficiently
- Processing of events in real time through its advanced Change Data Capture (CDC) Capability
- Providing data services to Oracle SOA suite
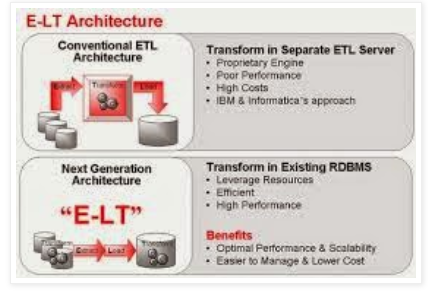
E-LT Architecture:
Traditional ETL:
ETL tools Operate by first extracting the data from various sources, transforming the data to proprietary or middle-tier ETL engine , and then loading the transformed data onto the target data warehouse or integration server.
Here data must be moved over the network twice:
Once between source and ETL server
Again Between ETL server and target data Warehouse
ETL engine performs data transformation row-by-row basis so it will be more difficult in some situations. Moreover, if you want to ensure the referential integrity by comparing data flow references against the value from target data warehouse, the referenced data must be downloaded from target to the engine, thus further increase the traffic in the network.
E-LT
Extract data from sources, load to tables into destination server, and then transform data on the target RDBMS using native SQL operators.
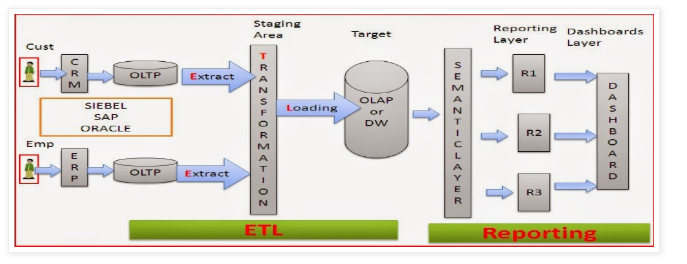
Data
Meaningful information is nothing but “Data”.
Types:
- Analytical Data (Data WareHouse)
- Transactional Data
Transactional Data
- Its run time data or day to day data
- It’s current and detail
- It’s useful to run Business
- It is used to store in OLTP (On Line transaction Processing)
- Source of Transactional data is Application
- Example ATM Transactions , Share market Transaction etc

Analytical Data
- It is useful analyze to the business
- It is historical and Summarized data
- It is stored in OLAP or Data Warehouse
- Source of Analytical Data is OLTP
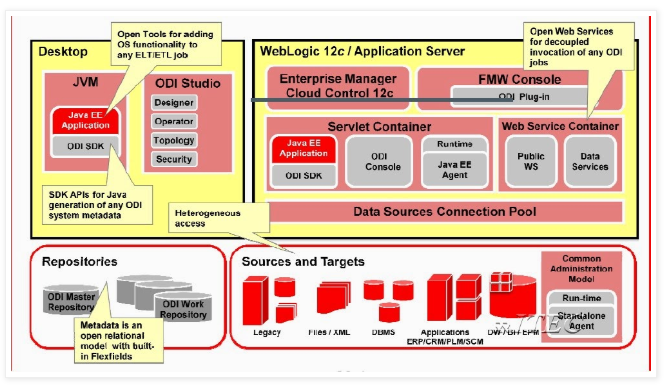
ODI Architecture
Data Warehouse Concepts
Data Warehouse:
A data warehouse is a relational database that is designed for query and analysis rather than for transaction processing.
It usually contains historical data derived from transaction data, but it can include data from other sources.
It separates analysis workload from transaction workload and enables an organization to consolidate data from several sources
Characteristics of a data warehouse (William Inmon):
- Subject Oriented
- Integrated
- Nonvolatile
- Time Variant
1.Subject Oriented:
Data warehouses are designed to help you analyze data.For example, to learn more about your company’s sales data, you can build a warehouse that concentrates on sales. Using this warehouse, you can answer questions like “How much sales happend last year for first quarter?” This ability to define a data warehouse by subject matter, sales in this case, makes the data warehouse subject oriented
2.Integrated:
Integration is closely related to subject orientation. Data warehouses must put data from disparate sources into a consistent format. They must resolve such problems as naming conflicts and inconsistencies among units of measure. When they achieve this, they are said to be integrated
3.Nonvolatile:
Nonvolatile means that, once entered into the warehouse, data should not change. This is logical because the purpose of a warehouse is to enable you to analyze what has occurred.
4.Time Variant:
In order to discover trends in business, analysts need large amounts of data. This is very much in contrast to online transaction processing (OLTP) systems, where performance requirements demand that historical data be moved to an archive. A data warehouse’s focus on change over time is what is meant by the term time variant
Data Warehousing Objects
Fact tables and dimension tables are the two types of objects commonly used in dimensional data warehouse schemas
Fact:
Fact tables typically contain facts and foreign keys to the dimension tables. Fact tables represent data, usually numeric and additive, that can be analyzed and examined. Examples include sales, cost, and profit.
Dimension tables:
Dimension tables, also known as lookup or reference tables, contain the relatively static data in the warehouse.Examples are customers or products.
Creating and Managing Topology for Oracle Technology
1. Creating Physical Architecture
Physical Architecture
a. The physical architecture defines the different elements of the information system, as well as their characteristics taken into account by Oracle Data Integrator
b. Each type of database (Oracle, DB2, etc.) or file format (XML, Flat File), or application software is represented in Oracle Data Integrator by a technology
c. The physical components that store and expose structured data are defined as “Data Server”
d. A data server is always linked to a single technology. A data server stores information according to a specific technical logic which is declared into physical schemas attached to this data server
Process to create Physical Architecture:
Data Server:
i. Open ODI Studio
ii. Connect to Master repository with Supervisor
iii. Go to Topology Navigator
iv. Expand Technologies and select Oracle Technology
v. Right click on it, select New Dataserver
vi. In the Definition mention as per below screenshot
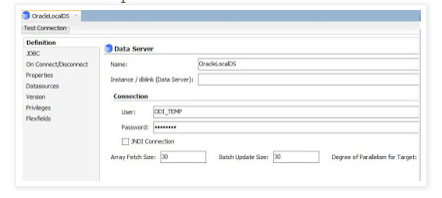
Name: PM_DEV_TGT_ORCL
User: DEV_TGT_ORCL
Password: Admin123
vii. In the JDBC tab mention as per below screenshot
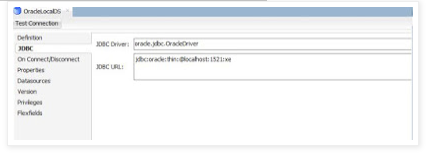
JDBC Drive: Select “oracle.jdbc.OracleDriver”
JDBC URL: jdbc:oracle:thin:@<host>:<port>:<sid>
viii. Click on Test Connection – Click Test – click Ok
ix. Hence Data server creation Completed
Physical Schema:
i. Right click on Data Server
ii. Select New Physical schema
iii. Enter details as mentioned below
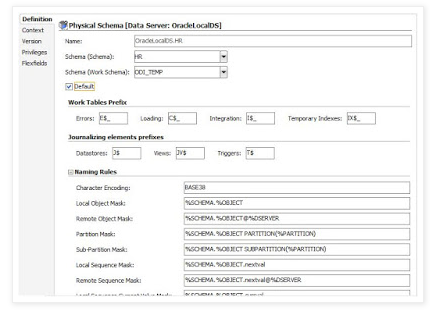
Schema (Schema) – Data Schema à ODI where inserts and updates target tables
Schema (Work Schema) – Work Schema à Schema where all temporary tables (E$_,C$_…) are created and dropped by ODI
iv. Click on Save – Click on Ok
2. Creating Context
Context:
Contexts bring together components of the physical architecture (the real Architecture) of the information system with components of the Oracle Data Integrator logical architecture (the Architecture on which the user works)
Process to Create:
i. Go to Topology navigator
ii. Expand Context Accordion
iii. Click on the New Context
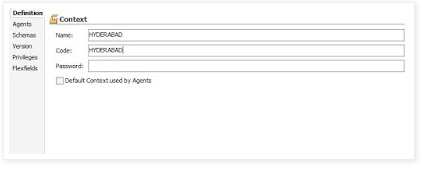
Name: Context Name
Code: Unique among various Repositories
v. Click on Save
3. Creating Logical Architecture
Logical Architecture:
a. The logical architecture allows a user to identify as a single Logical Schema a group of similar physical schemas – that is containing data stores that are structurally identical – but located in different physical locations
b. Logical Schemas, like their physical counterpart, are attached to a technology
c. All the components developed in Oracle Data Integrator are designed on top of the logical architecture. For example, a data model is always attached to logical Schema
Process to Create Logical Architecture:
i. Go to Topology Navigator
ii. Expand Logical Architecture
iii. Expand Technologies and right click on Oracle Technology
Click on New Logical Schema
Select Physical Schema for context
Click on Save
1. What is difference between ODI 11g and ODI 12c?

2.Different types of Repositories?
Ans: They are two types of Repositories
1. Master Repository and
2. Work Repository
Master Repository:
It holds information related to Topology and Security
Work Repository:
It stores information related to Designer and Operator
3.Different types of Work Repositories?
Ans: They are two types of Work Repositories
Execution Work Repository
Development Work Repository
4.What is the hierarchy of Master and Work Repositories?
Ans: We can have one Master and ‘n’ Work repositories. But each Work repository should be attach to only one Master Repository
5.What is the difference between ETL and ELT?
Ans: In ETL we should have Middle Tier Server Engine where as in ELT shouldn’t require Middle-Tier Server Engine. So it reduce cost. Network traffic is more for ETL where as for ELT less network traffic compare to ETL
6.What is meant by OLAP and OLTP?
Ans:
- OLAP – OnLine Analytic Process – Maintain Historical Data
- OLTP – OnLine Transaction Process – Daily Data (Business Data)
7.How many types of Navigators and their usage?
Ans: Four Types of Navigators are available.
- Designer – Development
- Operator – Monitoring
- Topology – Configuration
- Security – Provide Security
8.What is significant difference between Physical Schema and Logical Schema?
Ans: Physical Schema = Logical Schema + Context
For Example: Consider an Organization A whose Branches are A1,A2 and A3.
Consider the Structure of A1,A2 and A3 Schema’s are same but located in different Servers. By the EOD all the data stored in A1,A2 and A3 to be stored in A.
For above scenario, developer develops one mapping with one logical Schema , 3 Physical Schema (A1,A2 and A3)and 3 Context (A1_CTX,A2_CTX and A3_CTX) . While executing the mapping if he selects A1_CTX it loads to A1. (i.e., Logical_schema+A1_CTX = A1… ) . That means we can reuse same code to pick data from different schema’s.
9.What is an Agent and different types of Agents?
Ans: ODI agent is run time component which orchestrates the data integration process.
They are three types of Agents:
Standalone Agent – Light Weight
J2EE Agent – High Availability , Scalability, Security and better manageability
Colocated Standalone Agent – Combination both standalone and J2EE agent
10.What is Context and it’s purpose?
Ans: Contexts bring together components of the physical architecture (the real Architecture) of the information system with components of the Oracle Data Integrator logical architecture (the Architecture on which the user works).
For example, contexts may correspond to different execution environments (Development, Test and Production) or different execution locations (Boston Site, New-York Site, and so forth.) where similar physical resource exist.
11.What is an interface/Mapping?
Ans:Mappings are the logical and physical organization of your data sources, targets, and the transformations through which the data flows from source to target. We can create and manage mappings using the mapping editor, a new feature of ODI 12c.
12.What is a variable and different types of variables?
Ans:A variable is an object that stores a single value. This value can be a string, a number or a date. The variable value is stored in Oracle Data Integrator. It can be used in several places in your projects, and its value can be updated at run-time
- Refresh Variable
- Set Variable
- Declare Variable
- Incremental Variable
- Evaluation Variable
13.What is knowledge module and different types of KM’s?
Ans:Knowledge Modules (KMs) are code templates. Each KM is dedicated to an individual task in the overall data integration process
Types of KM’s:
- LKM – Loads heterogeneous data to staging area
- IKM – Integrate Data from staging area to target area
- RKM – Retrieves metadata to Oracle Data Integrator work repository
- SKM – Generates Data Manipulates web services
- CKM – Checks the constraints
- JKM – Used for CDC (Change Data Capture)
14.Different types of Reverse Engineering?
Ans: Two types of Reverse Engineering:
Standard Reverse Engineering
Customized Reverse Engineering
15.What is scenario?
Ans: The scenario code (the language generated) is frozen, and all subsequent modifications of the components which contributed to creating it will not change it in any way
16. What is difference between scenario and package?
Ans: Scenario is froze code we can’t do any modifications
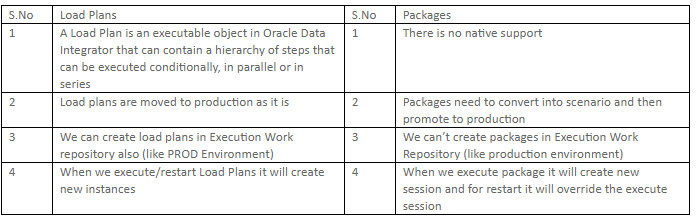
17. What is Load Plan and different types of Load Plans?
Ans:
A Load Plan is an executable object in Oracle Data Integrator that can contain a hierarchy of steps that can be executed conditionally, in parallel or in series
Types of Load Plans
- Parallel
- Serial
- Conditional
18.What is difference between Package and Load Plan?
19. How to perform exception Handling in ODI?
Ans:
Using ODISendMail and Eceptions in Loadplans
ODI processes are typically at the mercy of the entire IT infrastructure’s health. If source or target systems become unavailable, if network incidents occur, ODI processes will be impacted. When this is the case, it is important to make sure that ODI can notify the proper individuals. This post will review the techniques that are available in ODI to guarantee that such notifications occur reliably. When you create an ODI Package , one of the ODI Tool available to you for notification is ODISendMail
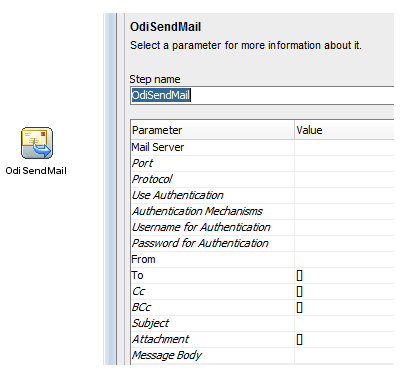
If we handle the exceptions at the load plan level there is no need to send the notification emails from the original package. What must do now is to create two separate packages: one to process the data, another one to handle the exceptions.
There are two main aspects to a load plan:
Steps: a set of scenarios that must be orchestrated, whether executions are serialized of parallelized
Exceptions: a series of scenarios that can be used in case one of the steps fails to execute properly.
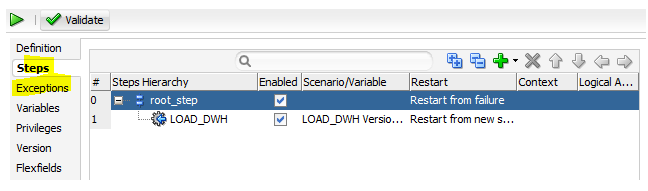
This exception will run a dedicated scenario whose sole purpose is to send a notification email.
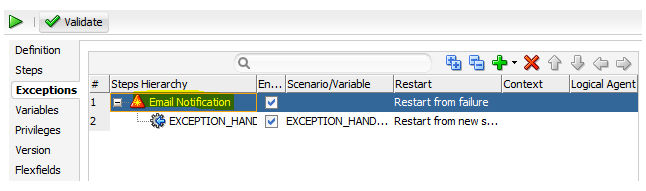
Load Plans Exception
When you edit the properties of the steps of the load plans, you can choose whether they will trigger the execution of an exception scenario or not. For each step, including the root step, you can define what the behavior will be in case of error:
Choose the exception scenario to run (or leave blank)
Run the exception scenario (if one is selected) and stop the execution of the load plan at this point
Run the exception scenario (if one is selected) and proceed with the rest of the load plan.
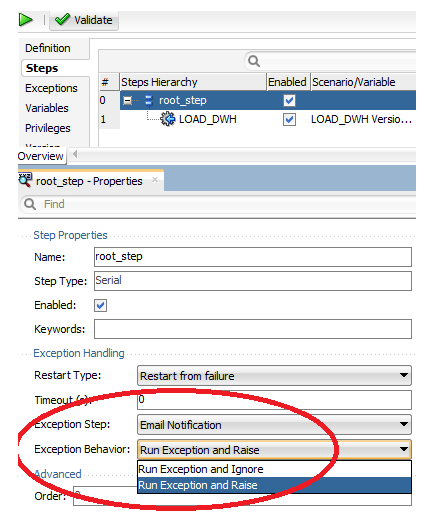
20. How to perform parallel execution and serial execution packages in ODI?
Ans:
Using Loadplans
You can arrange the packages in parallel , serially or based on specific conditions in or using loadplans
21.Can we reverse engineer Flat Files?
Ans: Yes, we can reverse engineer the flat files.
22.What are the advantages of standalone and J2EE agent?
Ans: J2EE Agent is highly available.
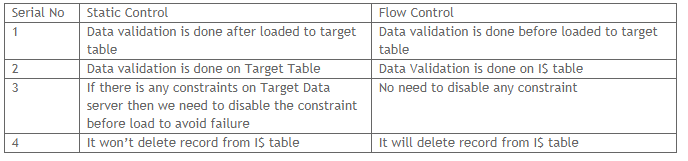
23. What is difference between Static and Flow control?
24. What is the difference between lookup and Join?
Ans: lookup is basically just like left outer join
25. How to load data from XML file to Relational database table?
Ans:
Example – XML to ORACLE Table using ODI
How to load data from XML to ORACLE Table using ODI 12c?
Source File:
<?xml version=”1.0″ encoding=”UTF-8″?>
<employeeDetails>
<employeeInfo>
<age>28</age>
<name>Trinesh</name>
</employeeInfo>
<employeeInfo>
<age>27</age>
<name>Shanthi</name>
</employeeInfo>
<employeeInfo>
<age>29</age>
<name>Tejesh</name>
</employeeInfo>
<employeeInfo>
<age>25</age>
<name>Vasavi</name>
</employeeInfo>
<employeeInfo>
<age>19</age>
<name>Nishith</name>
</employeeInfo>
</employeeDetails>
Target Table Structure:
CREATE TABLE REPLICA.EMPINFO
(EMPID NUMBER(3),
NAME VARCHAR2(50),
AGE NUMBER(3));
Pre-requisites:
Knows how to do topology configuration for Oracle Technology
Knows how to create model for Oracle
Steps:
Topology Configuration
- Expand Physical Architecture –> expand Technologies –> Right click on XML Technology and create new Dataserver
- In the definition provide the name of Dataserver (for e.g., XML_DS)
- Go to JDBC and Select as mention below
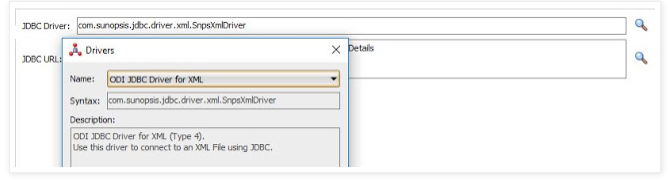
For JDBC URL: jdbc:snps:xml?f=<filename>[&s=<schema>&<property>=<value>…]
For example: jdbc:snps:xml?f=G:\ODI_FILES\ODI_XML\employee.xml&re=employeeDetails
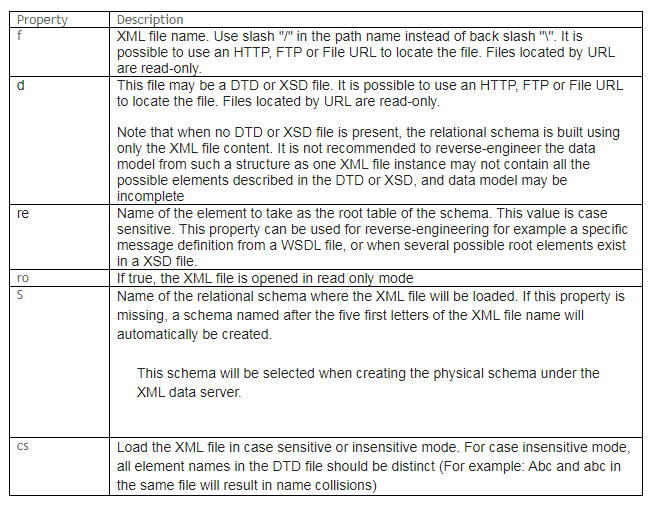
Save it and test the connection. You will get successful connection prompt
Right click on Data server and create Physical Schema (Provide the first five characters of file name if you didn’t provide property of s in JDBC URL)
Logical Architecture
Expand Technologies — Expand XML — Right click and new logical Schema (XML_LS)
Context
Link Logical Schema to Physical Schema
Designer:
Model
Create Model for XML technology as mention below
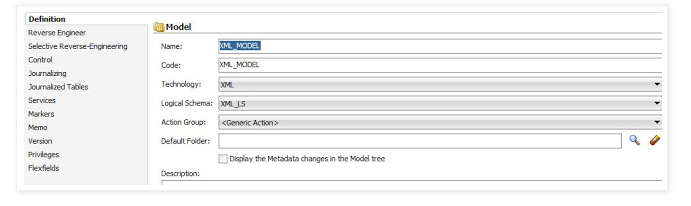
- Right click on Model and say click on reverse Engineering
- It will create two datastores as mention below
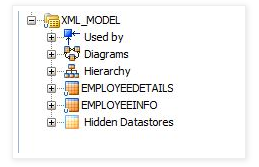
The standard reverse-engineering process will automatically reverse-engineer the table from the relational schema generated by the XML driver. Note that these tables automatically include:
Primary keys (PK columns) to preserve parent-child elements relationships
Foreign keys (FK columns) to preserve parent-child elements relationships
Order identifier (ORDER columns) to preserve the order of elements in the XML file
Project:
- Import Knowledge modules – LKM SQL to SQL and IKM SQL Control Append
- Create mapping — Drag drop the XML datastore (EMPLOYEEINFO) and Table datastore from Oracle Model (EMPINFO) and auto map it.
- For Employee Id map to the EMPLOYEEINFOORDER
- Go to physical tab and select above mention KM’s
- Execute the Mapping
Types of Variables in ODI
Variables:
A variable’s value is stored in Oracle Data Integrator. This value may change during the execution.
Declare Variable: When a variable is used in a Package Oracle strongly recommends that you insert a Declare Variable step in the Package. This step explicitly declares the
variable in the Package.
Refresh Variable: This variable step refreshes the variable by running the query specified in the variable definition.
Set Variable: There are two functions for this step:
Assign sets the current value of a variable.
Increment increases or decreases a numeric value by the specified amount.
Evaluate Variable: This variable step type compares the value of the variable with a given value according to an operator. If the condition is met, then the evaluation
step is true, otherwise it is false. This step allows for branching in Packages
27. What is sequence and different types of Sequence available in ODI?
Ans:
- A sequence is a variable automatically incremented when used. Between two uses the value is persistent.
- Standard sequences – whose current values are stored in the Repository.
- Specific sequences- whose current values are stored in an RDBMS table cell. Odi reads the value, locks the row and updates the row after the last increment.
- Native sequence – that maps a RDBMS-managed sequence.
28. What is User Functions?
Ans:
User functions allow you to define customized functions for
which you will define technology-dependent implementations. They are usable in
mappings and procedures.
29.What is Marker?
Ans:
A component of a project may be flagged in order to reflect a methodology or
organization. Flags are defined using markers. These markers are organized into
groups, and can be applied to most objects in a project
30.What is Scenario?
Ans:
When a package, mapping, procedure, or variable component has been fully
developed, it is compiled into a scenario. A scenario is the execution unit for production. You can generatete and regenerate scenarios in ODI
Scenarios can be scheduled for automated execution
31.What is meant by load balancing and how to do setup for it?
Ans: Load Balancing:
Oracle Data Integrator allows you to load balance parallel session execution between
physical agents.
An agent’s load is determined at a given time by the ratio (Number of running
sessions / Maximum number of sessions) for this agent.
To setup load balancing:
1. Define a set of physical agents, and link them in a hierarchy of agents
2. Start all the physical agents corresponding to the agents defined in the topology.
3. Run the executions on the root agent of your hierarchy. Oracle Data Integrator will
balance the load of the executions between its linked agents.
32. What is an agent and types of agents available in ODI?
Ans:
At design time, developers generate scenarios from the business rules that they have designed. The code of these scenarios is then retrieved from the repository by the Run-Time Agent.
This agent then connects to the data servers and orchestrates the code execution on these servers. It retrieves the return codes and messages for the
execution, as well as additional logging information – such as the number of processed records, execution time etc. – in the Repository.
The Agent comes in 3 different flavors:
- The Java EE Agent can be deployed as a web application and benefit from the features of an application server.
- The Standalone Agent runs in a simple Java Machine and can be deployed where needed to perform the integration flows.
- Colocated Standalone Agents can be installed on the source or target systems . They can be managed using Oracle Enterprise Manager and must be configured with an Oracle WebLogic domain. Colocated Standalone Agents can run on a separate machine from the Oracle WebLogic Administration Server
Migration:
1. How promote code from one environment another environment?
Ans: We can promote the code in 2 ways
a.Import and export scenarios
b. Smart Import and Smart Export Objects
2. What are different ways to promoting code ?
Ans:
a. Import and export scenarios
b. Smart Import and Smart Export Objects
3. What is difference between Smart import/Export and import/Export Scenario?
Ans: Import and Export we usually import or export that particular object or scenario but not the depend objects. Import and Export Scenarios is recommended for higher environment because we are no longer do development in higher environment (like UAT , PROD)
Smart Import and Smart Export is used to move code along with dependency object. This time of migration is recommended for lower environments like (DEV,QA) where we need to do development.
4. What is the approach you will follow for converting columns into rows?
Ans:
Using Un-Pivot
5. What is the approach you will follow for converting rows into columns?
Ans:
Using Pivot
6. How to load different departments records into different tables
Ans:
Using Split component in ODI 12c we can achieve it
7. How to load multiple files to single target table using single interface/Mapping in ODI?
using variables to loop through the files and a single mapping that loads the files to the target table
RANK:
RANK function is a built in analytic function which is used to rank a record within a group of rows. Its return type is number and serves for both aggregate and analytic purpose in SQL.
RANK (expression) WITHIN GROUP (ORDER_BY expression [ASC | DESC] NULLS
RANK () OVER (PARTITION BY expression ORDER_BY expression)
ROW_NUMBER:
assigns unique numbers to each row within the PARTITION given the ORDER BY clause
RANK() – behaves like ROW_NUMBER(), except that “equal” rows are ranked the same.
Primary Key Vs Unique Key
Primary Key:
- There can only be one primary key in a table
- In some DBMS it cannot be NULL – e.g. MySQL adds NOT NULL
- Primary Key is a unique key identifier of the record
Unique Key:
- Can be more than one unique key in one table
- Unique key can have NULL values
- It can be a candidate key
- Unique key can be NULL and may not be unique
Surrogate and Natural Key
A surrogate key is an artificial or synthetic key that is used as a substitute for a natural key.
A natural key is a key from within the data.
A surrogate key is a key that we introduce in the data so as to be able to
identify particular piece of information easily.
Usually, it is the unique identifier for each record.
Data WareHouse:
1. What are different types of Schemas?
Ans: Star Schema and Snow Flake schema
2. What is different between SnowFlake and Star Schema?
Ans:
3.What is Fact and Dimension?
Ans:
4.Different types of Facts?
Ans:
5.Different Types of Dimensions?
Ans:
6.What is meant by CDC?
Ans:
7. Different types of CDC?
Ans:
8.What is meant by SCD?
Ans:
A Slowly Changing Dimension (SCD) is a dimension that stores and manages both current and historical data over time in a data warehouse. It is considered and implemented as one of the most critical ETL tasks in tracking the history of dimension records.
9. Different types of SCD?
Ans:
We have 6 types of slow changing dimensions but 1, 2 and 3 are commonly used.
Type 0 — Fixed Dimension. No changes allowed
Type 1 —-No History
Type 2 —-Row versioning
Type 3 —-Previous Value Column
Type 4—-History Table
Type 6—-Hybrid SCD
Note! No Type 5 in commonly agreed definitions
slowly changing dimensions Explained
When organising a datawarehouse into Kimball-style star schemas, you relate fact records to a specific dimension record with its related attributes. But what if the information in the dimension changes?
Do you now associate all fact records with the new value? Do you ignore the change to keep historical accuracy?
Or do you treat facts before the dimension change differently to those after?
It is this decision that determines whether to make your dimension a slowly changing one. There are several different types of SCD depending on how you treat incoming change.
SCD
Type 0 – Fixed Dimension
- No changes allowed, dimension never changes
Type 1 – No History
- Update record directly, there is no record of historical values, only current state
Type 2 – Row Versioning
- Track changes as version records with current flag & active dates and other metadata
Type 3 – Previous Value column
- Track change to a specific attribute, add a column to show the previous value, which is updated as further changes occur
Type 4 – History Table
- Show current value in dimension table but track all changes in separate table
Type 6 – Hybrid SCD
- Utilise techniques from SCD Types 1, 2 and 3 to track change
In reality, only types 0, 1 and 2 are widely used, with the others reserved for very specific requirements. Confusingly, there is no SCD type 5 in commonly agreed definitions.
After you have implemented your chosen dimension type, you can then point your fact records at the relevant business or surrogate key. Surrogate keys in these examples relate to a specific historical version of the record, removing join complexity from later data structures.
Practical Scenario
We have a very simple ‘customer’ dimension, with just 2 attributes – Customer Name and Country:

However, Bob has just informed us that he has now moved to the US and we want to update our dimension record to reflect this. We can see how the different SCD types will handle this change and the pro/cons of each method.
Type 0
Our table remains the same. This means our existing reports will continue to show the same figures, maybe it is a business requirement that each customer is always allocated to the country they signed up from.
All future transactions associated to Bob will also be allocated to the ‘United Kingdom’ country.
Type 1
The table is updated to reflect Bob’s new country:

All fact records associated with Bob will now be associated with the ‘United States’ country, regardless of when they occurred.
We often just want to see the current value of a dimension attribute – it could be that the only dimension changes that occur are corrections to mistakes, maybe there is no requirement for historical reporting.
Type 2
In order to support type 2 changes, we need to add four columns to our table:
· Surrogate Key – the original ID will no longer be sufficient to identify the specific record we require, we therefore need to create a new ID that the fact records can join to specifically.
· Current Flag – A quick method of returning only the current version of each record
· Start Date – The date from which the specific historical version is active
· End Date – The date to which the specific historical version record is active
With these elements in place, our table will now look like:
This method is very powerful – you maintain the history for the entire record and can easily perform change-over-time analysis. However, it also comes with more maintenance overhead, increased storage requirement and potential performance impacts if used on very large dimensions.
Type 2 is the most common method of tracking change in data warehouses.
Type 3
Here, we add a new column called “Previous Country” to track what the last value for our attribute was.
Note how this will only provide a single historical value for Country. If the customer changes his name, we will not be able to track it without adding a new column. Likewise, if Bob moved country again, we would either need to add further “Previous Previous Country” columns or lose the fact that he once lived in the United Kingdom.
Type 4
There is no change to our existing table here, we simply update the record as if a Type 1 change had occurred. However, we simultaneously maintain a history table to keep track of these changes:
Our Dimension table reads:

Whilst our Type 4 historical table is created as:

Depending on your requirements, you may place both ID and Surrogate Key onto the fact record so that you can optimise performance whilst maintaining functionality.
Separating the historical data makes your dimensions smaller and therefore reduces complexity and improves performance if the majority of uses only need the current value.
However, if you do require historical values, this structure adds complexity and data redundancy overheads. It is generally assumed that the system will use Type 1 or Type 2 rather than Type 4.
Type 6
The ‘Hybrid’ method simply takes SCD types 1, 2 and 3 and applies all techniques. We would maintain a history of all changes whilst simultaneously updating a “current value” column on all records.

This gives you the ability to provide an element of change comparison without additional calculation, whilst still maintaining a full, detailed history of all changes in the system.
Personally, if this requirement came up, I would avoid the data redundancy of this extra column and simply calculate the current value using the “LAST_VALUE()” window function at run-time. Although this depends on your priorities between data storage and direct querying performance.